Text Predictor - Generating Rap Lyrics 📄
Language Modeling with Recurrent Neural Networks (LSTMs)

In today’s article, I am going to introduce you to the topic of Recurrent Neural Networks (RNNs), which will allow us to train agents that learn on sequential data like text, audio, video, etc. In this project, we will focus on the text predictions and after this post, you will be able to generate an infinite amount of your favorite rapper’s lyrics!
Like the ones generated by Kanye West’s RNN LSTM:
Right here, history
Where the day it’s face in. I really want some Marie weed
Hotel to aton will reach
If your cousing off on my free
You can’t even though too much on the old flowed
Man, and I pled them sinsulent
I heard that you’re from the road
Vermign and snald of mind car aware us said, you know its deal… Pokens on the chorus college
That’s that, God (You!)
I’m lost in the alane, at least three night
People do you told me, every night
Table of Contents
- Neural Networks (NNs)
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory (LSTM)
- Text Predictor
- Results
- What’s next?
In order to predict text using RNNs, we need to find out what RNNs are and how they work. Understanding Recurrent Neural Networks can be very simple and intuitive by using an analogy to the classic vanilla Neural Networks.
Neural Networks (NNs)
Let’s consider an example where we are going to build a predictive model that learns our habits. In our example we are going to have a very simple life - we will play basketball during the sunny days and read books during the rainy ones.

Our goal is to achieve a model that would predict our activity based on a weather input.

We aim to derive the weights of the model i.e the values in the red matrix that for given inputs would yield desired outputs.
In order to do so, we are going to train our network with the data of shape (weather, activity) that would reflect our real-life behavior. Assuming that we are going to stick to our plan of playing basketball on the sunny days and reading books during the rainy ones, there are going to be only two pairs of values that we are going to feed the model with - (☀️, 🏀) and (🌧, 📚).
After some training, i.e supplying input-output pairs (supervised learning), our red matrix of weights would approximately look as follows.

You can easily verify it.

Our predictive model correctly learned to associate sunny weather with playing basketball and rainy weather with reading books.
But what if we move to for example California and have a sunny weather all year round? In order to keep some sort of balance between physical and intellectual development, we should change our habits and interlace playing basketball with reading books. If we played basketball yesterday, we are going to read books today and play basketball tomorrow. We are going to stick with this routine of alternating activities.

Along with the above life changes we need to modify our predictive model accordingly. Classical Neural Networks won’t help us here as they don’t take into the equation sequences of inputs.
That’s where the Recurrent Neural Networks step in.
In the opposition to the regular Neural Networks, they are suited to handle and learn from sequential data which we have in our example.
Recurrent Neural Networks (RNNs)
Now as we don’t take weather input into consideration, we have only two values that can be treated as both inputs and outputs - playing basketball and reading books. Our simplified RNN model would look as follows.
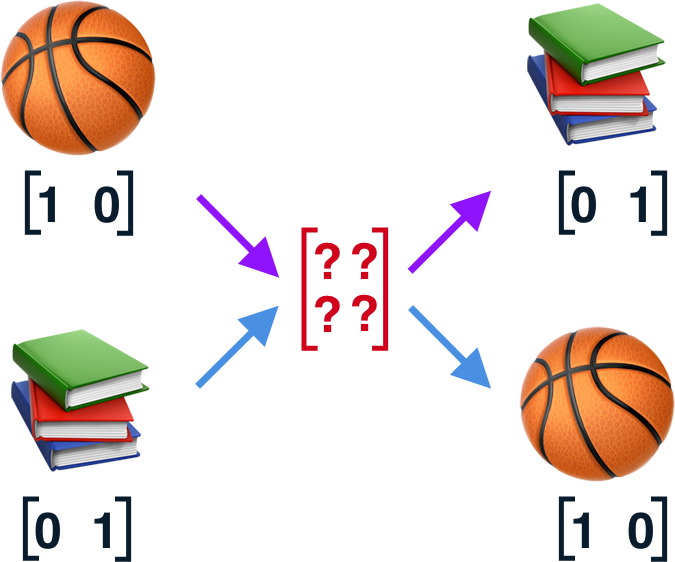
Now as we have our network structure defined, we can proceed with feeding it with some training data. Assuming that we are going to read books alternately with playing basketball, our training data would look like this (📚,🏀, … ,📚, 🏀 ).
After some training, we will end up with an approximated matrix of weights.
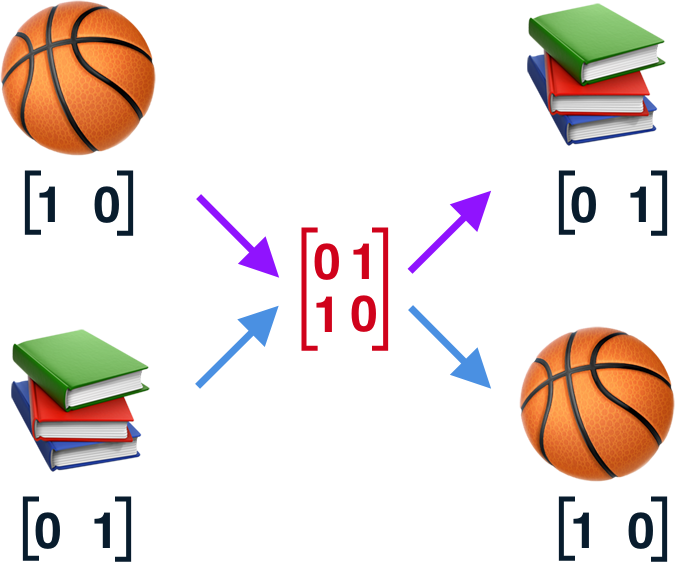
Finally, such model would correctly predict that if we recently played basketball, then we are going to read some books and similarly if we recently read books, we are going to play basketball next.
Despite different values, it looks exactly like the Neural Network from the previous example. It does so, because in fact in some sense it still is an NN and all its underlying concepts are unchanged beyond the fact that it recurrently takes outputs from the previous iterations as the inputs to the next ones.
It can be visualized as follows, where under the hood, each RNN unit is an NN.
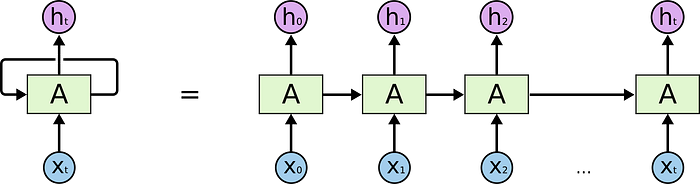
Above examples are just very simple and easy to grasp illustrations of the concept of RNNs. Their major feature is the fact that because of their recurrent nature, they can persist information.
It’s very humanlike because as humans we have prior knowledge and memory that helps us solve problems, usually without us being aware of this. Even such trivial activity like reading takes a huge advantage of this phenomenon. As we read, we don’t process each character independently, because each of them alone doesn’t mean anything. Letter ‘a’ is no better or worse than letter ‘b’. They start to make sense only if they are parts of higher level constructs like words, sentences and so on.
“Aoccdrnig to a rscheearch at Cmabrigde Uinervtisy, it deosn’t mttaer in waht oredr the ltteers in a wrod are, the olny iprmoatnt tihng is taht the frist and lsat ltteers be at the rghit pclae. The rset can be a toatl mses and you can sitll raed it wouthit porbelm. Tihs is bcuseae the huamn mnid deos not raed ervey lteter by istlef, but the wrod as a wlohe.”
RNNs strive to achieve this ability with its recurrent network architecture that allows to persist information during consecutive learning steps.
Let’s consider a text predictive model that is trying to predict a missing word in a sentence.
That which does not kill us makes us (…).
I suppose that most of us know the correct answer which is ‘stronger’.
How do we know that?
Probably because it’s one of the most popular quotes of all time and we simply remember it from books, movies, tv shows etc.
Luckily for our text predictive model, it was fed with a dataset that contained this phrase and it appeared recently so it also was able to use its memory to derive a valid solution.
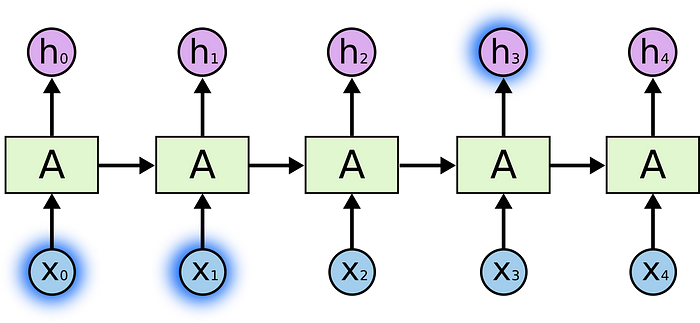
We were able to find a relevant information in our model because it was relatively close, we didn’t have to look too far back.
Let’s consider another example of our text predictive model. This time we are going to feed our model with the whole collection of Charles Darwin’s works (I actually did it, check). Then let’s ask our model to predict a missing word in a given phrase.
On the Origin of (…)
This riddle is definitely harder than the previous one, but those of you who are familiar with Darwin’s works probably know that the missing word is “Species” and the whole phrase is the title of his most famous book on the theory of evolution.
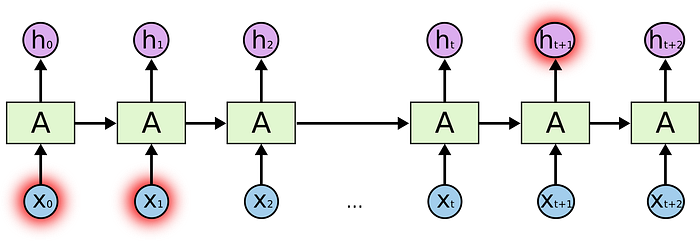
Unfortunately our model was unable to predict it correctly. This phrase doesn’t occur in the book very often and its occurrence in the title was too far back to be remembered.
For us, human readers, it’s obvious and intuitive that if a phrase appears in a title, it has to be a crucial part of the book and even if it occurs only there, in contrast to RNNs we are still going to remember it.
Even though RNNs fail in handling such long-term dependencies there are other ways to manage them successfully.
One of them are Long Short-Term Memory Networks (LSTMs), which we are going to briefly analyze and implement in this project.
Long Short-Term Memory (LSTM)
While RNNs remember everything to some limited depth, LSTMs learn what to remember and what to forget.
It allows LSTMs to reach and exploit memories that are beyond RNNs range, but due to their perceived importance, they were remembered by LSTMs.
Sounds promising, and definitely worthwhile implementing, right?
Let’s dive into the details!
Recurrent Neural Networks in general, have a simple structure, of repeating modules through which data flows. Standard RNNs are usually built of simple tanh layers.

LSTMs on the other side contain much more complicated units.

It may look overwhelming at first, but it can be simplified to the following and easier to comprehend diagram.

As you can see above, a LSTM cell has 3 gates.
- Input gate decides whether a given information is worth remembering.
- Forget gate decides whether a given information is still worth remembering. If it doesn’t, it gets deleted.
- Output gate decides whether a given information is relevant at a given step and should be used.
But how this mysterious decision-making process actually works?
Each gate is a layer with an associated weight. During each step, it takes an input and performs a sigmoid function that returns a value from a 0–1 range, where 0 means to let nothing through and 1 to let everything through.
Afterward, each layer’s value will be updated through the back-propagation mechanism. It allows the gates to learn over time which information is important and which is not.
Now as we are familiar with the high-level concepts that stand behind RNNs extended with LSTMs, we can proceed to the actual implementation of our Text Predictor project.
Talk is cheap show me the code, Linus Torvalds
Text Predictor
Data
Since we are going to implement a character-level model, we are going to split all lines of our dataset into lists of characters. Afterward, we are going to detect unique characters and corresponding frequency scores. The lower the frequency score, the more popular the associated char (among the dataset).
Then we are going to create a vocabulary, which is a dictionary of the following shape.
{unique_char:frequency_score}Next step, would be to create our working tensor. Probably the easiest way to imagine it would be to take our input dataset and replace each character with its frequency score.
To give you a better understanding of what’s going on, let’s create a tensor for an initial phrase of our Kanye’s dataset.
Input:
“Kanye, can I talk to you for a minute?Tensor:
[28 46 4 5 15 1 19 0 20 4 5 0 23 0 3 4 10 21 0 3 2 0 15 2
13 0 24 2 9 0 4 0 16 6 5 13 3 1 38] Now that we have our working tensor defined, let’s divide it into batches. Our model’s goal is to optimize in a way that for given inputs would yield desired outputs. In order to do so, we need to supply both input and target batches.
For the sake of simplicity, let’s assume that our sequence length is 5. Knowing this we can set the first input batch to the 5 initial elements of a working tensor.
Since our model is a char-level one, our goal is to predict the next character for a list of previous characters. The easiest way to create a target batch that satisfies this requirement would be to subscript the tensor with a +1 shift compared to the input batch.
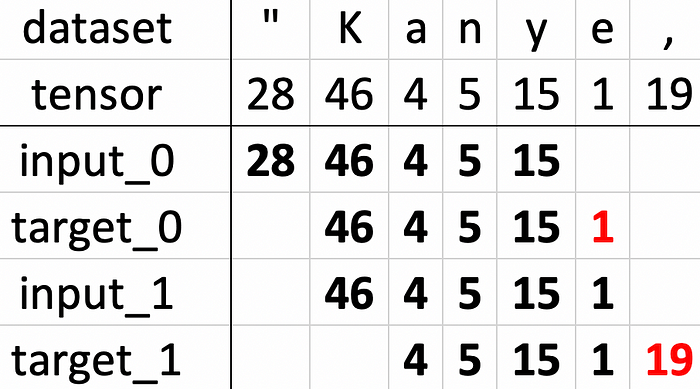
We generate as many input/target pairs as possible for supplied params and tensor length. All these pairs create a one training epoch.
Now that we have our data layer defined, let’s feed our model with it.
Algorithm
Let’s start with some basic data preparation/initialization.
Subsequently, let’s create an infinite loop of training epochs.
Within every epoch, let’s iterate through every batch, feed our model (TensorFlow implementation details can be found here) with input/target pairs and finally persist current state and loss.
And finally collect stats, sample text and output logs.
Results
Ultimately we can proceed to our main goal - to generate rap lyrics! I encourage you to collect the lyrics of your favorite rapper, concatenate them into a single file
cat song1.txt song2.txt > text_predictor/data/<dataset>/input.txtand run
python text_predictor.py <dataset>Output file with the rap lyrics along with the training plot will be automatically generated in the dataset’s directory.
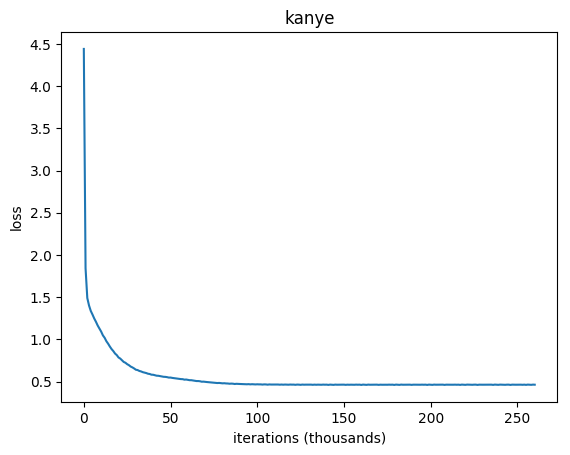
You should expect results comparable to the below ones.
Kanye West’s lyrics predictions were generated using the following parameters.
Selected dataset: kanye
Batch size: 32
Sequence length: 25
Learning rate: 0.01
Decay rate: 0.97
Hidden layer size: 256
Cells size: 2
Tensor size: 330400
Batch size: 32
Sequence length: 25
Batches size: 413Kanye’s input dataset contains lyrics from the following albums: ‘The College Dropout’, ‘808s & Heartbreak’, ‘Yeezus’, ‘Late Registration’, ‘Graduation’, ‘My Beautiful Dark Twisted Fantasy’, ‘Watch the Throne’ and ‘The Life of Pablo’.
Iteration: 0
9hu71JQ)eA”oqwrAAUwG5Wv7rvM60[*$Y!:1v*8tbkB+k 8IGn)QWv8NR.Spi3BtK[VteRer1GQ,it”kD?XVel3lNuN+G//rI’ Sl?ssm
NbH # Yk2uY”fmSVFah(B]uYZv+2]nsMX(qX9s+Rn+YAM.y/2 Hp9a,ZQOu,dM3.;im$Jca4E6(HS’D
[itYYQG#(gahU(gGoFYi)ucubL3 #iU32 8rdwIG7HJYSpDG*j,5
As expected, our model knew nothing in the beginning, so it just generated a random text.
Iteration: 1000
Am our 200 shought 2 and but
One we -fuckister do fresh smandles
Juco pick with to sont party agmagle
Then I no meant he don’t ganiscimes mad is so cametie want
What
Mama sumin’ find Abortsimes, man
We can see that our model learned how to form some words and how to structure the text. Each line has a moderate length and starts with a capital letter.
Iteration: 3000
Moss for a kice the mowing?[Verse 1]
I play this better your pictures at here friends
Ever sip head
High all I wouldn’t really what they made thirise
And clap much
Our text predictor learned how to form a dataset specific constructs like ‘[Verse 1]’. Moreover, it made significantly less vocabulary errors then in the previous iterations.
Iteration: 25000
Through the sky and I did the pain is what what I’m so smart
Call extry lane
Make man flywing yet then you a represent
And paper more day, they just doing with her
This that fast of vision
Although the generated text still doesn’t make much sense, we can see that the model learned how to generate almost errorless verses.
Iteration: 207000
Right here, I was mailing for mine, where
Uh, that’s that crank music nigga
That real bad red dues, now you do
Hey, hey, hey, hey
Don’t say you will, if I tried to find your name!
I’m finna talk, we Jine?
Ok, ooh oh!
Bam ba-ah-man, crack music nigga
(We look through to crew and I’m just not taking out
Turned out, this diamondstepragrag crazy
Tell my life war[Hook]
Breakfies little lights, a South Pac-shirt
Track music nigga
(La la la la la la la lah, la la la la la lah)
After more than 200 thousands of learning iterations, our Kanye AI learned how to sing 🙂.

While the above samples of AI-generated lyrics probably don’t convey any meaningful (at least for the humans) message, we can clearly see that the model learned how to correctly mimic the style of a provided input dataset. Given the fact that our RNN LSTM learned everything from scratch and initially had no sense of words or sentences, not to mention the English language, its results are pretty amazing! Furthermore, it learned solely from a very small dataset of Kanye’s lyrics and its results would probably be even better with a bigger dataset.
What’s next?
Even though generating rap lyrics was so much fun, we don’t have to stop there. In fact, I didn’t, and I created and sampled other datasets. It’s a great way of learning how RNNs work and I encourage you to experiment and do the same. If you need some inspiration, feel free to check the full list of datasets I have prepared. They are all available here.
kanye - Kanye West's discography (332 KB)
darwin - the complete works of Charles Darwin (20 MB)
reuters - a collection of Reuters headlines (95 MB)
war_and_peace - Leo Tolstoy's War and Peace novel (3 MB)
wikipedia - excerpt from English Wikipedia (48 MB)
hackernews - a collection of Hackernews headlines (90 KB)
sherlock - a collection of books with Sherlock Holmes (3 MB)
shakespeare - the complete works of William Shakespeare (4 MB)Don’t forget to check the project’s github page.
Questions? Comments? Feel free to leave your feedback in the comments section or contact me directly at https://gsurma.github.io.
And don’t forget to 👏 if you enjoyed this article 🙂.

